

Arnaud Cassone sur la direction de Fosca Aquaro lance un nouveau logiciel interactif crée sur‐mesure pour les artistes “S-watch”.
Il est basé sur l’enseignement du chant vers un approche innovant qui s’appuie sur l’utilisation du numérique.

En se basant sur une analyse des ondes cérébrales, il permet d’identifier les notes et les accords qui entrent le plus en résonance avec l’élève et en se servant de celles-ci, de donner accès à de nouvelles facultés d’apprentissage.
S-Watch peut-être utiliser aussi dans des autres institutions comme les EMS par les audio thérapeutes pour soigner la maladie d’Alzheimer.
Ça marche comment ?
S-Watch utilise un casque EEG (Mindwave et bientôt Muse), un ordinateur et un microphone. Il analyse les ondes cérébrales ( Delta, Theta, Low Alpha, High Alpha, Low Beta, High Beta, Low Gamma, High Gamma, ), le taux d’attention ( focus ) et de méditation/ relaxation, et enregistre les données dans un tableau en relation avec la fréquence captée par le microphone.
Quels algorithmes sont utilisés ?
Le spectre audio est découpé en 4096 segments, en utilisant la transformation de Fourier discrète. Il est choisi le segment dont la crète est la haute comme valeur centrale.
Les tableaux enregistrés peuvent contenir de grandes quantités de plages de fréquences similaires, afin de réduire le nombre de données à une quantité compréhensible, il est effectué une moyenne des données par fréquence.
Comment obtenir un résultat ?
S-Watch permet de modéliser physiquement les résultats dans un tableau croisé.
Afin d’obtenir un résultat utilisable il faut prendre en compte les facteurs extérieurs à l’échantillonnage, qui sont multiples et les réduire au maximum. (bruits de fond, stress ). Cette imprécision peut être réduite par la multiplication des prises et la durée des échantillonnages. Plus la quantité de donnée augmente, plus l’imprécision diminue.

Quelles sont les bien faits et les résultats qu’on obtient utilisant S-Watch?
Une meilleure prise de conscience de l’importance du souffle dans sa propre endurance, Une amélioration de la concentration, de la compréhension du texte,
Une amélioration de l’apprentissage musicale à différents niveaux :
ressenti, interprétation, extériorisation des sentiments.
A quoi/qui est utile S-Watch?
- Enfants avec des problèmes de concentration et hyperactivité
- Enfants/ados timides
- Dyslexie
- Perte de la mémoire
- Gestion des émotions Gestion du stress.
A la recherche de sa propre tonalité.
Ayant pu constater le manque de fiabilité ou de transparence des outils disponibles pour les audio thérapeutes, ainsi que les techniques, peu claires, sujettes aux interprétations des uns et aux imprécisions des autres, Fosca Aquaro, audio thérapeute et musicienne, a décidé de prendre contact avec moi pour me proposer ce projet qui m’a tout de suite intéressé.
C’est ainsi que nous avons décidé de réaliser un logiciel de traitement des données EEG permettant d’obtenir des résultats clairs et réutilisables.
L’objectif initial du projet était de permettre de trouver la tonalité propre à chacun en effectuant des enregistrements d’ondes cérébrales, la méthode choisie est celle d’une modélisation physique des plages fréquentielles dans un tableau croisé que les données enregistrées définissent de manière empirique.
C’est à dire qu’aucune extrapolation ni interpolation ne sont effectuées, les résultats du tableau proviennent directement des enregistrements. Cela permet une interprétation objective des données.
Les premiers développements ont permis de connaître les possibilités et contraintes de la méthode, et ainsi définir des objectifs plus précis. Il en est sorti que de manière générale, les sujets sont sensibles à plusieurs fréquences de manière optimale.
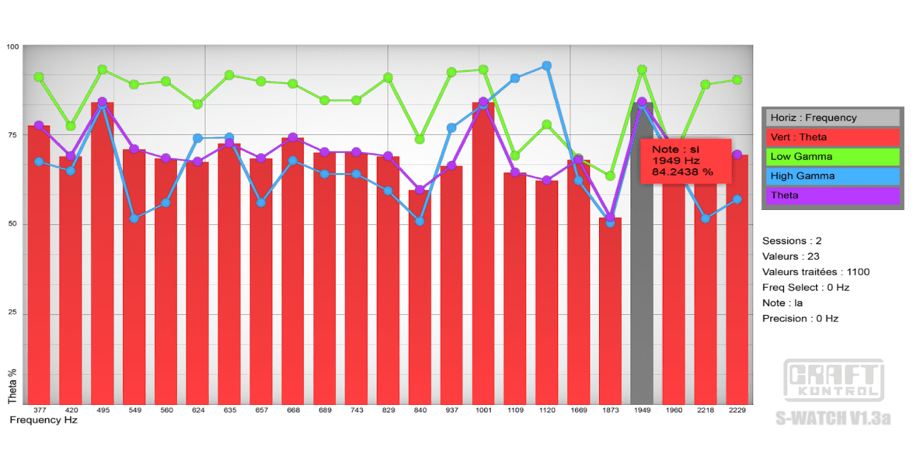
Par exemple prenons le cas de “robert”, figure 2, ses enregistrements montrent qu’en onde thêta, les trois plus fortes fréquences sont 495Hz, 1000Hz et 1949Hz, il convient donc de prendre en compte les accords dans la génération musicale. Une autre question vient à se poser, celle de la simultanéité ou de l’alternance des notes, à laquelle une étude devra répondre.
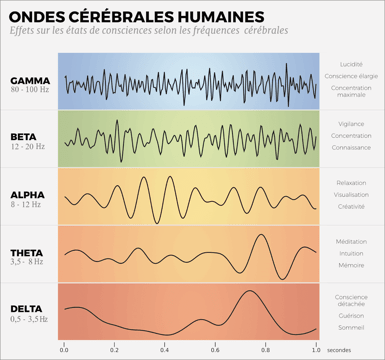
Les ondes cérébrales chez l’humain étant connues *1 et leurs fonctions déjà dégrossies, je ne m’étendrais pas sur ce sujet, mais précisément sur les ondes thêta (4,8 à 8Hz) et les ondes gamma (40 à 80Hz). Les ondes gamma étant connues pour s’activer lorsque le cerveau est en état de perception, et les ondes thêta lors de la mémorisation, on peut en déduire que la fréquence sonore entendue ou chantée obtenant la plus haute quantité d’ondes thêta et gamma est la meilleure tonalité dans un cadre d’étude ou de travail.
Bien entendu, il convient de prendre cette information avec prudence, un grand nombre de facteurs extérieurs viennent perturber le processus de collecte des données. Etat émotionnel, sons extérieurs, fond diffus etc… Mais on peut estimer que c’est une mesure fiable car non extrapolée, et, à partir du moment où le nombre d’enregistrements est suffisant, atténuée de ses interférences extérieures.
La probabilité pour que ces facteurs extérieurs se reproduisent de la même manière sur tous les enregistrements est quasi nulle. Il convient d’effectuer des enregistrements sur de longues période et à des moments différents pour minimiser les erreurs.
L’analyse des données EEG est le coeur du logiciel. Il permet d’afficher les ondes cérébrales en rapport avec la fréquence audio, et de connaître la moyenne de chacune sur tous les enregistrements afin d’en extraire une note globale exprimée en pourcentage. Ainsi on peut savoir par exemple, que la fréquence 1949 Hz exprime 93% d’ondes gamma et 83% d’ondes thêta etc…


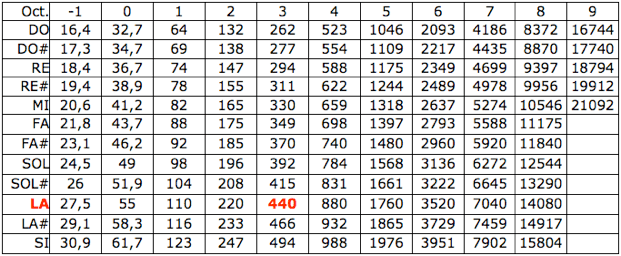
Une partie du logiciel sera plus orientée vers une utilisation musicale, puisque la fréquence est directement convertie en note selon le tableau de la gamme tempérée *2. Ainsi il est possible de connaître la note et le groupe de notes les plus efficaces sur une onde donnée.
Il peut être réalisé une mélodie et des accords spécifiques afin d’augmenter un type d’onde chez le sujet et, par extension, augmenter ses facultés au moment de l’écoute.
Il est évident que la réalisation d’une telle musique est sujette à controverse. Il existe deux options, la première étant de prendre les résultats tels quels, et de produire des sonorités correspondant aux fréquences les plus fortes dans le domaine voulu, sous forme de fond diffus.
L’autre est de produire une musique selon les règles universelles et d’y appliquer les résultats du programme afin d’être plus facilement assimilables. Évidemment, une interprétation musicale sera obligatoire afin d’éviter les dissonances. Une étude serait nécessaire afin d’évaluer la méthode la plus efficace.
Existe-t-il une relation entre les ondes sonores et les ondes lumineuses ? La lumière et le son sont tous deux des ondes évoluant sur leur plage de fréquence propre. Il n’existe pas de corrélation connue entre les deux bandes du spectre, le son audible évoluant autour de 20 Hz à 20 000 Hz et la lumière à partir des 800 000Hz.
La méthode choisie pour l’instant sera celle du consensus regroupant un maximum de propositions *3.
Ce consensus vise à appliquer de manière uniforme le spectre colorimétrique sur celui du spectre audio d’une gamme *4.
A terme, l’objectif du logiciel sera de définir statistiquement une gamme de couleurs en analysant le résultat des ondes cérébrales sur un stimuli lumineux d’une certaine couleur.
Il est possible de connaître de la même manière que pour le son, les fréquences lumineuses les plus efficaces sur une onde donnée. Il devient possible de réaliser un environnement visuel et sonore spécifique à chacun.
C’est afin de tenter de répondre à ces questions que nous avons décidées, Fosca Aquaro et moi-même, de commencer la réalisation de S-Watch, un logiciel d’analyse d’EEG dédié aux audio thérapeutes.
Le programme et en cours de développement, et s’étoffera de nouvelles fonctions comme l’ajout du support du casque EEG Muse, de nouvelles fonctions d’analyse, un module de colorimétrie spectrale, une utilisation plus didactique et un analyseur vibratoire pour le chant.
Arnaud Cassone
S-Watch developer
Craft Kontrol
Sources & references
*1 Rythme cérébral (Wikipedia)
*2 Gamme tempérée (Wikipedia)
*3 La couleur, éditions Le léopard d’or, 1994, pp. 63-82 – Philippe Junod
*4 À la recherche de correspondances entre sons et couleurs (Futura Science)
En savoir plus: http://varianteconcept.ch
{kind=link}